Web content enumeration tools
Summary
Note: The original article was posted on my company blog https://blog.sec-it.fr/.
Perimeter discovery is an important step during a web pentest and can, in some cases, lead to a website compromise. In order to carry out this recognition, several tools are available, including web content enumeration tools:
| Name | Version* | First release | Last Release | Language |
|---|---|---|---|---|
| Dirb | 2.22 | 2005/04/27 | 2014/11/19 | C |
| DirBuster | 1.0-RC1 | 2007 | 2013/05/01 | Java |
| Dirsearch | 0.4.1 | 2014/07/07 | 2020/12/08 | Python3 |
| FFUF | 1.2.1 | 2018/11/08 | 2021/01/24 | Go |
| Gobuster | 3.1.0 | 2015/07/21 | 2020/10/19 | Go |
| Wfuzz | 3.1.0 | 2014/10/23 | 2020/11/06 | Python3 |
| BFAC (Bonus) | 1.0 | 2017/11/08 | 2017/11/08 | Python3 |
* this post has been written in Feb. 2021
Other tools such as Rustbuster, FinalRecon or Monsoon exists and won’t be fully described since they’re less known and used. They’ll be part of the synthesis.
Dirb
Dirb is a web content scanner written in C and provided by The Dark Raver since 2005.
DIRB is a Web Content Scanner. It looks for existing (and/or hidden) Web Objects. It basically works by launching a dictionary based attack against a web server and analyzing the response.
The last release of this tool was 5 years ago, in 2014, with the version 2.22. The package is provided by most of pentesting Linux releases such as Black Arch and Kali Linux.
The tool is provided with many wordlists, including big.txt, and common.txt (its default wordlist). Dirb is also provided with two utilities: html2dic which is an equivalent of cewl and gendict which is an equivalent of crunch, both are used for wordlist generation.
Despite dirb is one of the oldest web discovery tools, it proposes most of the advanced options such as custom headers, custom extensions, authenticated proxy and even interactive recursion. Unfortunately, the tool is one of the rarest that doesn’t provide multithreaded capabilities.
Pros
- Specify multiple wordlists (comma separated)
- Recursive mode (by default, or using
-Roption for interactive mode)
Cons
- No multithreaded option
- Only GET method
- No fancy filters
- Only one output options
DirBuster
DirBuster is a web content scanner written in Java provided the OWASP Foundation since 2007. The project is no longer maintained by OWASP and the provided features are now part of the OWASP ZAP Proxy. The last release of the tools was version 1.0-RC1 in 2008. DirBuster has the particularity to provide a GUI :
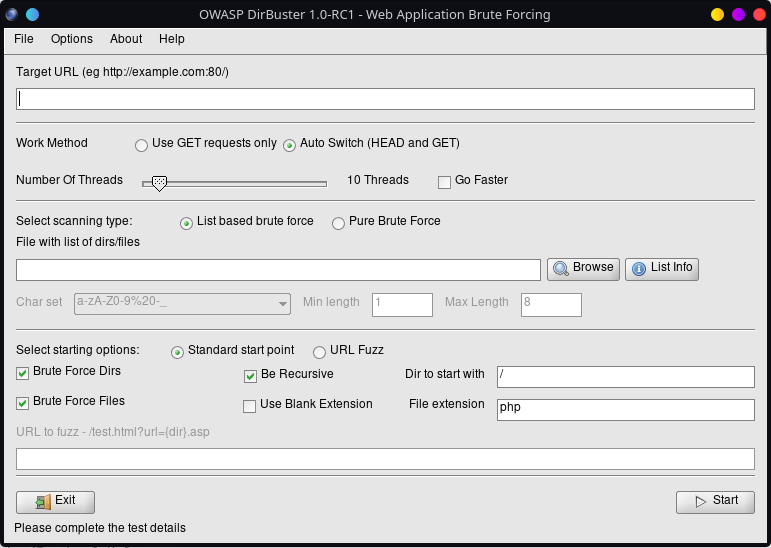
Even if the project is not proposed by OWASP anymore, source of the tool can be found on SourceForge. The tool is also provided by most of pentesting Linux distributions.
The tool is packaged with 8 wordlists including directory-list-1.0.txt and apache-user-enum-2.0.txt.
Pros
- WebSite scrapping (extract folders from
srcandhrefattributes) - Support digest access authentication
- Specify Fuzzing point in URL
- Reports in XML, CSV or TXT
Cons
- Only GET/HEAD method
- Java GUI
Dirsearch
Dirsearch is a command-line tool designed to brute force directories and files in web servers. The tool is written in Python3 since 2015 but was designed in 2014 with Python2. Dirsearch is still maintained and the last release was in December 2020.
As a feature-rich tool, dirsearch gives users the opportunity to perform a complex web content discovering, with many vectors for the wordlist, high accuracy, impressive performance, advanced connection/request settings, modern brute-force techniques and nice output.
As you can see, dirsearch provides many options to perform wordlist transformation such as extension exclusion, suffix, extension removal. Dirsearch even provide 429 - Too Many Requests error handling, raw requests handling, and regex checks. Dirsearch is provided with a default wordlist named dicc.txt which contain %EXT% tags which will be replaced with user-defined extensions.
Finally, dirsearch provide multiple report formats including text, JSON, XML, Markdown and CSV.
Pros
- Multiple URLs and CIDR support
- Multiple extensions check
- Support multiple wordlists with wordlist manipulation
- Support raw requests with
--rawoption, and any HTTP method with-m. - Colorful output with many export formats and regex filters
Cons
- Lots of options, custom scan may be long to configure
- No quick way to fuzz a specific part of an URL
FFUF
FFUF (Fuzz Faster U Fool) is a web fuzzer written in Go. The tool is quite recent (first release in 2018) and is actively updated. Unlike the previous tools, FFUF aims to be an HTTP fuzzing tool which can be used not only for content discovery but also for parameters fuzzing. Thanks to its design, FFUF also has the ability to fuzz headers such as VHOST.
Such as Dirsearch, FFUF provide filter and “matcher” options (including regex) to sort results, and a lot of output formats (including JSON and XML). FFUF is the only one to provide multi-wordlist operation mode, such as attack type in BurpSuite intruder. This mode can be used for bruteforce attack or complex fuzzing discovery.
Finally, we can note that the option -D allow us to reuse specific Dirsearch wordlists sur as dicc.txt.
Pros
- “Replay-proxy” option which can be associated with other tools such as BurpSuite
- Multi-wordlist operation modes
- Colorized output
- Custom / Auto filtering calibration
Cons
- lots of options, custom scan may be long to configure
Gobuster
As indicated by his name, Gobuster is a tool written in Go. The first release of gobuster was in 2015 and the last one in October 2020. Gobuster is a powerful tool with multiple purpose :
Gobuster is a tool used to brute-force: URIs (directories and files) in websites. DNS subdomains (with wildcard support). Virtual Host names on target web servers. Open Amazon S3 buckets
As mentioned in the project description, Gobuster has been originally created to avoid Dirbuster Java GUI and that do support content discovery with multiple extensions at once.
As said in the tools description, Gobuster aim to be a simple tool without any fancy options. Note that Gobuster is provided without any wordlist.
Pros
- Multiple extensions
-doption to discover backup files- DNS, VHOST and S3 options
Cons
- No recursion
- Single Wordlist
- No regex match
- Only one output format (TXT)
Wfuzz
Wfuzz is a web fuzzer written in Python3 and provided by Xavi Mendez since 2014.
Wfuzz has been created to facilitate the task in web applications assessments and it is based on a simple concept: it replaces any reference to the FUZZ keyword by the value of a given payload.
The tool is still maintained with a recent release in November 2020. The package is provided by most of pentesting Linux releases.
The tool is provided with a lot of wordlists: General (big.txt, common.txt, medium.txt…), Webservices (ws-dirs.txt and ws-files.txt), Injections (SQL.txt, XSS.txt, Traversal.txt…), Stress (alphanum_case.txt, char.txt…), Vulns (cgis.txt, coldfusion.txt, iis.txt…) and others.
Such as Fuff, Wfuzz replace the FUZZ keyword by a payload from a given wordlist. Wfuzz provides multiple filters including regex filters (--ss/hs) and supports multiple outputs (JSON, CSV, …). Also, Wfuzz is one of the rarest tools to support both basic auth, NTLM auth and digest auth.
Pros
- Encoders (urlencode, base64, uri_double_hex…) and scripts
- Encoding chaining
- Basic/NTLM/Digest authentication
- Colorized output
Cons
- Single wordlist
Bonus - BFAC
BFAC (Backup File Artifacts Checker) is not a tool design to search for new folders, files or routes, but a tool designed to search for backup files.
BFAC (Backup File Artifacts Checker) is an automated tool that checks for backup artifacts that may disclose the web application’s source code. The artifacts can also lead to leakage of sensitive information, such as passwords, directory structure, etc. The goal of BFAC is to be an all-in-one tool for backup-file artifacts black box testing.
Given a list of files URI, BFAC will attempt to recover associated backup files with a hardcoded list of tests. For example, for the file /index.php, BFAC will not only attempt to recover /index.php.swp and /index.php.tmp, but also includes tests such as /Copy_(2)_of_index.php, /index.bak1 or /index.csproj.
As you can imagine, BFAC should be used as a complement of previous tools. It supports most of the expected features such as proxy support, custom headers and different outputs.
Pros
- Complementary Tool
- Efficient with fewer requests than a common web discovery tool
Cons
- Even if the tool is still maintained, the repository only provides one release
Use-cases
Simple discovery on PHP applications
The main use of these tools is file discovery on a common web server, such as a PHP website running on an apache2. Searching for files on this kind of web server often leads to HTTP errors such as 404 - File not found, 403 - Forbidden or HTTP success such as 200 - OK. Other HTTP status codes may be encountered, like 302 - Found, 429 - Too Many Requests, 500 - Internal Server Error…
Depending on the server configuration, an auditor may or may not include specific HTTP status code during file discovery. The default configuration on most of the tools is to hide 404 - File not found from results. Displayed status codes may vary between tools but 200 - OK is the most common displayed result.
i.e., by default, Dirsearch will print not only 200 status code but also 301, 302, etc.
$ dirsearch -u http://localhost/
$ dirsearch -u http://localhost/ -e php
$ dirsearch -u http://localhost/ -e php,php5,sql -w /usr/share/wordlists/raft-large-words.txt -f
Note : By default dirsearch only replaces the
%EXT%keyword with extensions. Using-fflag will force dirsearch to add extensions for a given wordlist. This option is useless if your wordlist already contains file extensions.
The same task can be accomplished by the other tools :
$ dirb http://localhost/ /usr/share/wordlists/raft-large-words.txt -X php,php5,sql
$ gobuster dir -u http://localhost/ -w /usr/share/wordlists/raft-large-words.txt -x php,php5,sql
$ ffuf -u http://localhost/FUZZ -w /usr/share/wordlists/raft-large-words.txt -e php,php5,sql
$ wfuzz --hc 404 -w /usr/share/wordlists/raft-large-words.txt -w exts.txt http://localhost/FUZZFUZ2Z
Webserver with a custom page for error 40X
Sometimes, server won’t reply as expected for your tools and will reply a 403 error instead of a 404 error, or worst a 200 status code with a custom error page.
In this case, the auditor must configure his tool to match with the server answer. For the 403 case, the first solution is to exclude 403 results from his tool :
$ dirb http://localhost/ /usr/share/wordlists/raft-large-words.txt -X php,php5,sql -N 403
$ dirsearch -u http://localhost/ -e php,php5,sql -w /usr/share/wordlists/raft-large-words.txt -f -x 403
$ gobuster dir -u http://localhost/ -w /usr/share/wordlists/raft-large-words.txt -x php,php5,sql -b 403,404
$ ffuf -u http://localhost/FUZZ -w /usr/share/wordlists/raft-large-words.txt -e php,php5,sql -fc 403
$ wfuzz --hc 404,403 -w /usr/share/wordlists/raft-large-words.txt -w exts.txt http://localhost/FUZZFUZ2Z
With this solution the auditor may miss interesting 403 errors. The second option is to filter more precisely the content you’re not looking for.
If the 403 error is a custom page or if you got a 200 status code with an error message, you may filter web pages by their content and not with their status code. Tools provide multiple way to perform that: you can either filter by page size (assuming the error page is always the same size), or you can filter per words or regex present in the web page.
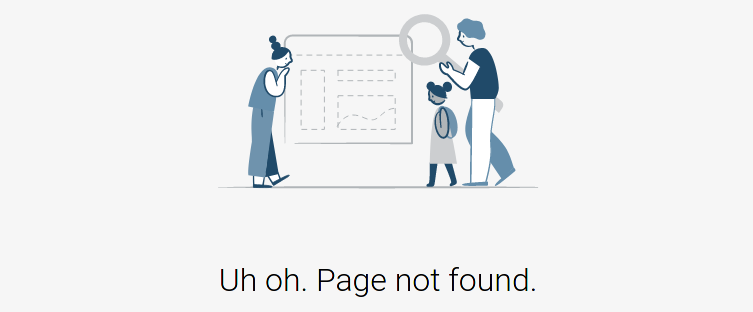
i.e., if a website returns a 200 HTTP status code with an HTML page containing the sentence Page not found, you may filter with the following :
$ dirsearch -u http://localhost/ --exclude-texts="Page not found" -e php,php5,sql -w /usr/share/wordlists/raft-large-words.txt -f
$ ffuf -u http://localhost/FUZZ -fr "Page not found" -w /usr/share/wordlists/raft-large-words.txt -e php,php5,sql
$ wfuzz --hs "Page not found" --hc 404 -w /usr/share/wordlists/raft-large-words.txt -w exts.txt http://localhost/FUZZFUZ2Z
Not that this method is not available for every tool.
Fuzzing on Rest API
With the evolution of Web development standards, auditors encounter more and more varied web routing techniques. Therefore, it’s not rare that resources are accessible through dynamic routes. That’s the case of RESTfull WEB API where certain resources must be fuzzed at the middle of an URI.
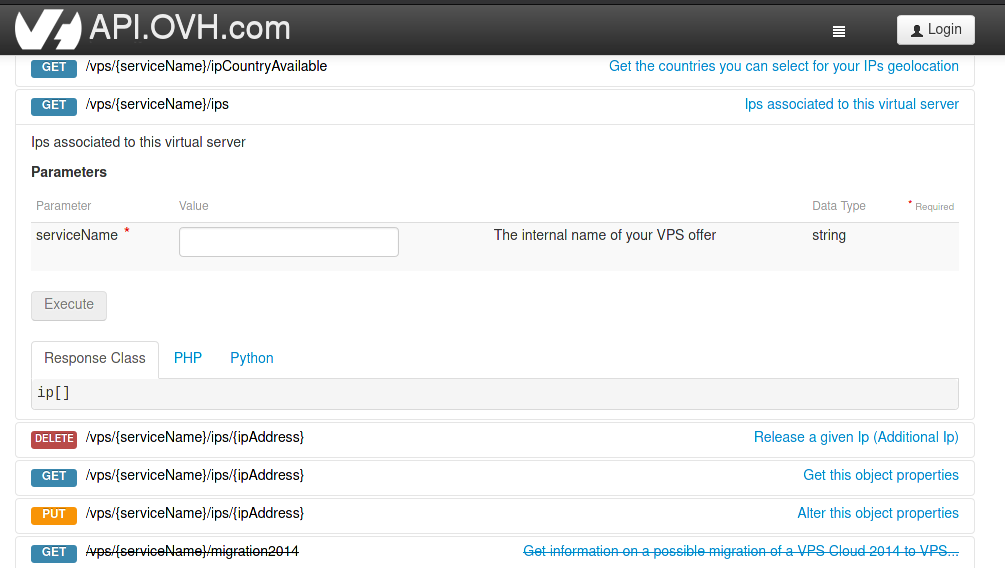
Let’s take the example of a REST API where the route /vps/{serviceName}/ips is available with GET requests (and where the route /vps/{serviceName} doesn’t exist). To enumerate this parameter, you’ve got 3 possibilities :
Reuse the previous examples and set/ipsas an extension 🧐 ;- Use suffix option on tools if available ;
- Use a dedicated fuzzing tool such as
ffuforwfuzzto perform precise parameter fuzzing (recommended).
$ dirsearch -u http://localhost/vps/ --suffixes /ips -w /usr/share/wordlists/raft-large-words.txt
$ ffuf -u http://localhost/vps/FUZZ/ips -w /usr/share/wordlists/raft-large-words.txt
$ wfuzz --hc 404 -w /usr/share/wordlists/raft-large-words.txt http://localhost/vps/FUZZ/ips
POST IDOR with incremental ID
Sometimes resources location is based on a more complex parameter such as Accept-Language header, HTTP POST parameter or even IP address.
During a pentest, SEC-IT auditors encounter a vulnerability allowing users to download PDF on page /files/pdf with POST parameter {"objectId": "X"} where X is an integer. The vulnerability itself was an IDOR (Insecure Direct Object Reference) : a user could download any PDF without privilege restriction.
The problem is that even if the vulnerable parameter was a pseudo-incremental ID, there was a random step between each ID which makes the exfiltration harder without any tool.
To perform this PDF exfiltrations, web fuzzer like ffuf and wfuzz can be used to fuzz the objectId POST parameter :
$ ffuf -u http://localhost/files/pdf -X POST -d '{"objectId" : "FUZZ"}' -w /usr/share/wordlists/ints.txt
$ wfuzz -z file,/usr/share/wordlists/ints.txt -d '{"objectId" : "FUZZ"}' http://localhost/files/pdf
Comparative table
Without further ado, here is a comparative table of the different tools discussed in this post :
{kind=link}
| Dirb | Dirbuster | Dirsearch | FFUF | GoBuster | Wfuzz | Rustbuster | FinalRecon | Monsoon | BFAC | |
|---|---|---|---|---|---|---|---|---|---|---|
| Language | C | Java | Python3 | Go | Go | Python3 | Rust | Python3 | Go | Python3 |
| First release | 27/04/2005 | 2007 | 07/07/2014 | 08/11/2018 | 21/07/2015 | 23/10/2014 | 20/05/2019 | 05/05/2019 | 12/11/2017 | 08/11/2017 |
| Last release | 19/11/2014 | 01/05/2013 | 08/12/2020 | 24/01/2021 | 19/10/2020 | 06/11/2020 | 24/05/2019 | 23/11/2020 | 28/10/2020 | 08/11/2017 |
| Current version | 2.22 | 1.0-RC1 | 0.4.1 | 1.2.1 | 3.1.0 | 3.1.0 | 1.1.0 | no versionning | 0.6.0 | 1.0 |
| License | GPLv2 | LGPL-2 | GPLv2 | MIT | Apache License 2.0 | GPLv2 | GPLv3 | MIT | MIT | GPLv3 |
| Maintained | No | No | Yes | Yes | Yes | Yes | Yes | Yes | Yes | Yes |
| GUI/CLI | CLI | GUI (Java) | CLI (colorized by default) | CLI (colorize option) | CLI | CLI (colorize option) | CLI | CLI (colorized by default) | CLI (colorized by default) | CLI (colorized by default) |
| Profile options file | No | No but ability to modify default threads, WL and extentions | Yes (default.conf) | Yes (-config) | No | Yes (--recipe) | No | No | Yes (-f) | No |
| Output | No (-o, text only) | Yes (XML, CSV, TXT) | Yes (JSON, XML, MD, CSV, TXT) | Yes (JSON, EJSON, HTML, MD, CSV, ECSV) | No (-o, text only) | Yes (-o, JSON, CSV, HTML, Raw) | No (-o, text only) | Yes (-o, XML, CSV, TXT) | No (--logfile, text only) | Yes (JSON, CSV, TXT) |
| Multithread | No | Up to 500 | Yes (-t) | Yes (-t) | Yes (-t) | Yes (-t) | Yes (-t) | Yes (-t) | Yes (-t) | Yes (--threads) |
| Delay | Yes (-z) | Yes (Rate limit) | Yes (-s) | Yes (-p), accept range | Yes (--delay) | Yes (-s) | No | No | Yes (--requests-per-second) | Yes (Rate limit) |
| Custom Timeout | No | Yes | Yes (--timeout) | Yes (-timeout) | Yes (--timeout) | Yes (--req-delay) | No | Yes (-T) | No | Yes (--timeout) |
| Proxy | Yes (-p/-P, socks5) | Yes (not specified, authenticated) | Yes (--proxy, http/socks5) | Yes (-x, http, see issue 50) | Yes(--proxy, http(s) ) | Yes (-p) Socks4 / Socks5 / HTTP (unauthent) | No | No | Yes (SOCKS5/HTTP(s) authenticated) | Yes (--proxy, http(s)/socks5 authenticated) |
| Auth | Basic | Basic / Digest / NTLM | Basic with Headers | Basic with Headers | Basic (-U/-P) | Basic / Digest / NTLM | Basic with Headers | No | Basic (-u) | Basic with Headers |
| Default WL | common.txt (4614) | No | dicc.txt (9000) | No | No | No | No | dirb_common.txt (4614) | No | N/A |
| WL provided | Yes (more than 30) | Yes (8) | Yes (5) | No | No | Yes (more than 30) | No | Yes (3) | No | N/A |
| Recursion | By default, switch available | Yes | Yes (-r) | Yes (-recursion) | No | Yes (-R) | No | No | No | N/A |
| Recursion depth | No but interactive mode available | No | Yes (-R) + interactive | Yes (-recursion-depth) | N/A | Yes (-R) | N/A | N/A | N/A | N/A |
| Multiple URLs | No | No | Yes (-l) / CIDR | Yes (using wordlist of hosts) | No | Yes (using wordlist of hosts) | No | No | No | Yes (-L) |
| Multiple WL | Yes (commas separated) | No | Yes, commas seperated | Yes (repeat -w) | No | Yes (repeat -w) | Yes (for multiple Fuzzing point) | No | No | N/A |
| WL Manipulation | No | No | Yes (lots of transformations) | No | No | Yes (using encoders and script) | No | No | No | N/A |
| Encoders | No | No | No | No | No | Yes | No | No | No | N/A |
| Single Extension | Yes (-X/-x) | Yes | Yes (-e) | Yes (-e) | Yes (-x) | Yes | Yes (-e) | Yes (-e) | Yes | N/A |
| Multiple Extensions | Yes (-X/-x) | Yes (commas separated) | Yes (-e, commas separated) | Yes (-e, commas separated) | Yes (-x, commas separated) | Yes (with given wordlist) | Yes (-e, commas separated) | Yes (-e, commas separated) | No | N/A |
| Custom User-Agent | Yes (-a/-H) | Yes | Yes (--user-agent) + random | Yes (with header -H) | Yes (-a) + random | Yes (with header -H) | Yes (-a) | No | Yes (with header -H) | Yes (-ua) |
| Custom Cookie | Yes (-c/-H) | Yes (through headers) | Yes (--cookie) | Yes (with header -H) | Yes (-c) | Yes (-b) | Yes (with header -H) | No | Yes (with header -H) | Yes (--cookie) |
| Custom Header | Yes (-H) | Yes | Yes (-H) + Headers file | Yes (-H) | Yes (-H) | Yes (-H) | Yes (-H) | No | Yes (-H) | Yes (--headers) |
| Custom Method | No | No | Yes (-m) | Yes (-x) | Yes (-m) | Yes (-X) | Yes (-X) | No | Yes (-X) | No |
| URL fuzzing (at any point) | No | Yes | Not by design but can be bypassed using --suffixes | Yes | No | Yes | Yes (fuzz mode) | No | Yes (fuzz mode) | N/A |
| Post data fuzzing | No | No | No | Yes (-d) | No | Yes (-d) | Yes (fuzz mode) | No | Yes (fuzz mode) | N/A |
| Header fuzzing | No | No | No | Yes (-H) | No | Yes | Yes (fuzz mode) | No | Yes (fuzz mode) | N/A |
| Method fuzzing | No | No | No | Yes (-X FUZZ) | No | Yes (-X FUZZ) | Yes (fuzz mode) | No | Yes (fuzz mode) | N/A |
| Raw file ingest | No | No | Yes (--raw) | Yes (-request) | No | No | No | No | Yes (--template-file) | No |
| Follow redirect (302) | Yes + switch (-N) | Yes + switch | Yes (-F) | Yes (-r) | Yes (-r) | Yes (-L) | No | No | Yes (--follow-redirect) | No |
| Custom filters | No | No | Yes (--excludes-*, based on text, size, regex) | Yes (-m*, -f*, based on code, size, regex) | Limited (status code, -s/-b) | Yes (based on code, words, regex) | Yes (based on code, string) | No | Yes (size,code,regex) | Yes (code, size or both) |
| Backup files option | No | No | No | No | Yes (-d) | No | No | No | No | Yes |
| Replay proxy | No | No | Yes (--replay-proxy) | Yes (-replay-proxy) | No | No | No | No | No | No |
| Ignore certificate errors | By default ? | By default ? | By default | By default, (switch with -k) | Yes (-k) | By default | Yes (-k) | Yes (-s) | Yes (-k) | By default |
| Specify IP to connect to | No | No | Yes (--ip) | No | No | Yes (--ip) | No | No | No | No |
| Vhost enumeration | No | No | No | Yes | Yes | Yes | Yes | No | Yes | N/A |
| Subdomain enumeration | No | No | No | Yes | Yes | Yes | Yes | Yes | Yes | N/A |
| S3 enumeration | No | No | No | No | Yes | No | No | No | No | N/A |
About
The original article was published on my company’s blog https://blog.sec-it.fr/.
You can find SEC-IT at the address https://www.sec-it.fr.
Part of this content is under MIT License / © 2021 SEC-IT.